Summary
主要通过 raft 论文的解读,理解 raft 一致性算法
Raft 是一种用来管理日志复制的一致性算法,脱胎于 Paxos 但是比 Paxos 更容易理解
将一致性算法细分为了 3 个子问题,并对每个子问题进行了详细提供明确的说明
- 选主
- 日志复制
- 安全性
论文的内容概述
复制状态机 Section2
通常的 RSM 是通过日志复制来实现的,而保证复制日志的一致性则依赖一致性算法,常见的一致性算法系统通常包括以下几点特性
- 安全性,一般再不考虑拜占庭问题下,出现的 网络延迟、分区、丢包重复问题不会导致系统出现异常结果
- 高可用,多数节点存活状态下,系统可用
- 不依赖时间来保障一致性
- 多数一致性,少数响应缓慢节点不影响整体性能
Paxos 的问题 Section3
这部分主要介绍了 Paxos 在时间中的问题 Paxos 主要有两个障碍
- 难以理解
即使是最简单的
Paxos单决议的子集,都是难以理解的 - 没有为实际实现提供一个良好的基础
其次是复杂度很高,难以用于实践
Raft 的设计目标 Section4
Raft 的设计目标
- 为构建实际的实现提供良好的基础
- 可理解
Raft 为提高可理解性做出的两个方式
- 细分问题
- Leader Election(选主)
- Log replication (日志复制)
- Safety (安全性)
- Membership change (成员变更)
- 简化状态空间
Raft 一致性算法 Section5-8
评估Raft 与相关工作 Section9-10
Section9 主要通过一些数据证明 raft 的易于理解、正确性以及性能的说明
Section10 主要是简单的介绍了一写与 raft 相关或类似的项目 VR , zookeeper
Raft 一致性算法 ATTACH
- Raft 算法概述

Raft 算法的关键属性
Raft 保障下列特性在任何时刻都是有效的
Election Safety: 任何一个
term中,最多只有一个Leader可以被选出Leader Append-Only:
Leader不会覆写或删除任何日志entry,只允许追加entryLog Matching : 如果两个日志
Entry有相同的index和term,那么在此之前的日志是绝对一致的Leader Completeness: 如果一个日志
entry在一个term中被提交,那么这条日志entry必然存在于更高序号的term的Leader的日志中State Machine Safety: 如果一个服务确认了给定所以的日志,其他服务绝对不会使用相同的索引
Raft 一致性算法细分为了一下 3 个子问题
- Leader election: 当现有的 Leader 失败时,需要选举出一个新 Leader
- Log replication: Leader 必须接受来自客户端的日志条目,并将其复制到集群中,并保证其他日志与自己的日志保持一致。
- Safety: 如果一个服务确认了给定所以的日志,其他服务绝对不会使用相同的索引
Raft basic ATTACH
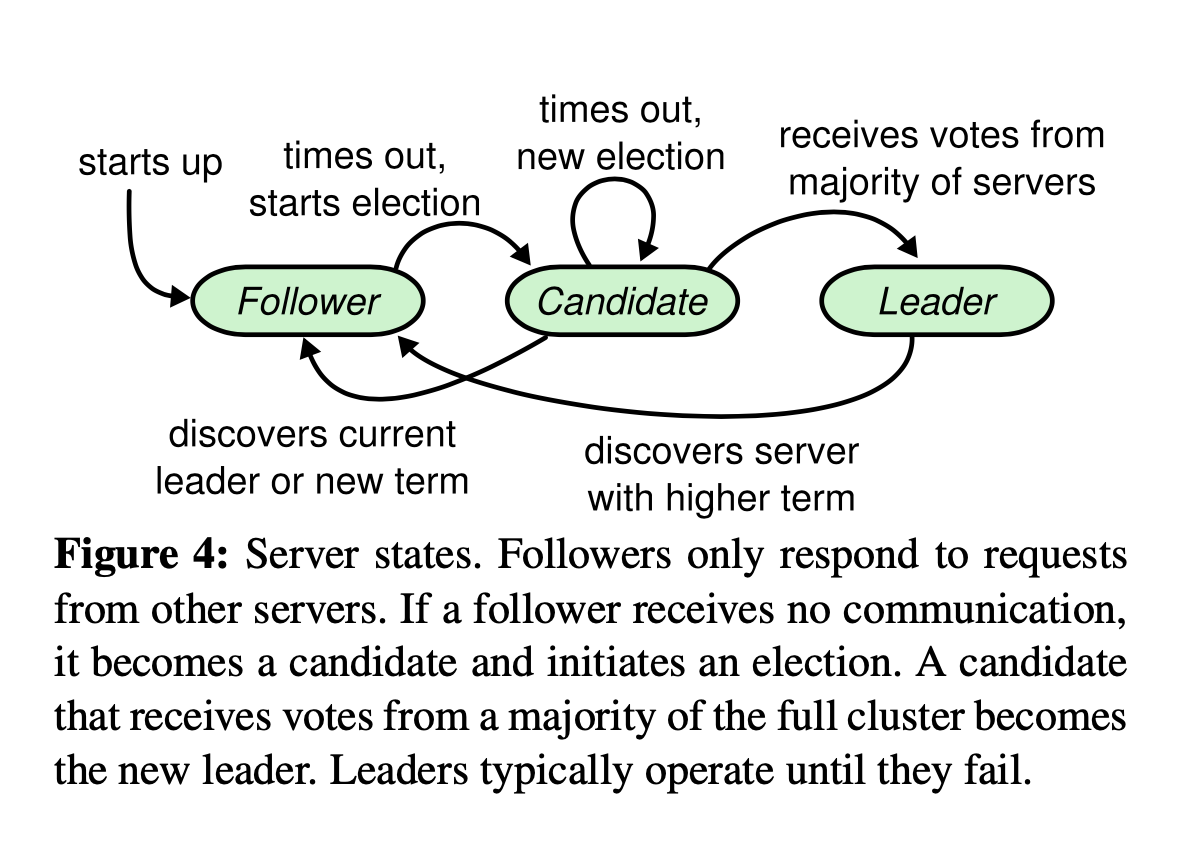
状态
在任意时刻,Server 只有 leader , follover , candidate 三种状态
- follower: 不处理请求,只响应来自 leader 与 candidate 的请求
- leader: 处理所有来自 client 的请求
- candidate: 在竞选新 leader 的情况出现
状态变更图
term
Raft 将时间划分为任意长度的任期。
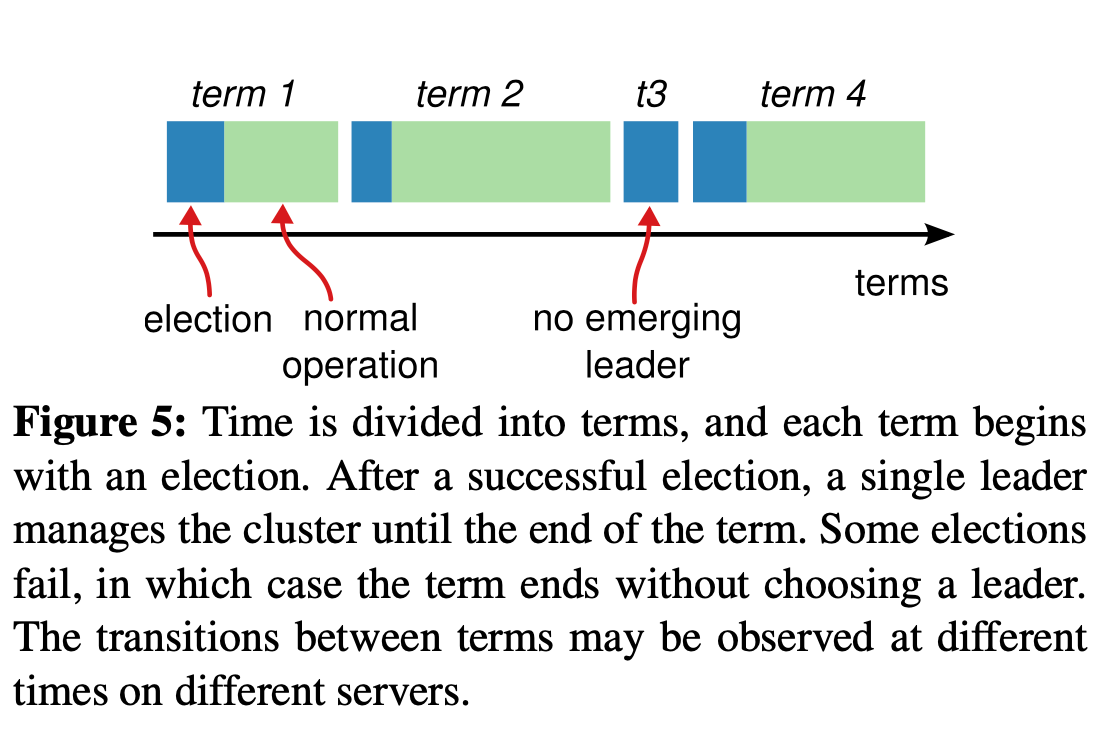
通过 terms 作为一个逻辑时钟,服务间的每次交互都会交换各自的 term ,当 term 比对方大时,会更新自己的 term 为较大值
RPC
RequestVoteRPCS
AppendEntriesRPCs
InstallSnapshotRPC
通过并行请求提高效率
Raft Leader Election
Leader 通过保持心跳来与 Follwer 同步状态,当出现 election timeout ,即在一个周期时间内,没有收到来自 Leader 的心跳,即认为 Leader 不可达并发起新一轮的选举
选举开始时,follower 会增加自己的 term 并将自己转为 candidate,通过 RequestVote RPC 进行投票后,会有三种情况
- 赢得选举
- 其他服务赢得选举
- 选举超时,没有服务赢得选举
通过多数原则及先到先得原则保证最多只有一个 candidate 可以赢得选举。
canidate 处理 RPC 请求的情况
own term < rpc term时,恢复到follower状态own term > rpc term时,拒绝请求新一轮选举
Raft 通过随机超时选举时间来解决冲突,不采用随机化会导致类似饥饿的问题
Raft Log Replication
leader 选举
日志复制采用了类似 zk 的全局主写入方案,能保证全局一致性
一旦选举出领导者,领导者开始处理客户端请求,并将命令追加到日志中。
领导者通过 AppendEntries RPC 将日志条目复制到跟随者。
当日志条目在大多数服务器上安全复制后,领导者将该命令应用到其状态机,并返回结果给客户端。
日志提交
commited 机制 ,当 Leader 提交了一个日志 Entry ,那么 raft 会保证该 Entry 的持久化,并且最终会应用于所有可用的服务
日志条目在 Leader 将其复制到大多数服务器后被提交。一旦提交,它将是持久的,并最终被所有状态机应用。 领导者跟踪最高的提交日志索引,并在未来的 RPC 中包含该索引,以确保跟随者更新。
日志匹配属性:
如果两个日志条目具有相同的索引和任期,它们存储相同的命令。
如果两个日志条目具有相同的索引和任期,它们在所有前面的条目上是相同的,从而确保一致性。
AppendEntries 进行一致性检查,确保维持这一属性。
处理崩溃与不一致:
如果跟随者的日志与领导者的日志不一致,领导者会通过强制跟随者的日志与自己的日志一致来解决不一致问题。领导者会找到两者日志匹配的最新位置,删除跟随者日志中不匹配的条目,并发送自己的日志条目覆盖它们。
Leader 维护一个 nextIndex,指示下一条将发送给跟随者的日志索引。当跟随者的日志不一致时, AppendEntries 检查会失败,领导者会递减 nextIndex 并重试,直到日志一致。
Raft Safety
Raft 协议需要确保所有的领导者都已提交该条目,这样才能确保日志的一致性。如果一个条目来自之前的任期,它可能还未被所有服务器接受,因此不能立即认为它已提交。这个问题是 Raft 协议确保一致性和安全性的关键部分,尤其在处理领导者崩溃和恢复时需要特别注意。
Raft 不会通过计数副本的方式提交来自旧任期的日志条目。只有当前领导者任期中的日志条目,才会通过副本计数的方式提交。
关于安全性的证明 这部分感兴趣的可以自己看看原文
Raft Follower 与 Candidate 崩溃
主要说了 Follower 于 Candidate 崩溃时的策略,相对 Leader 崩溃的会简单不少
- 重试,直到服务恢复正常
- 当业务完成后 crash , 通过 幂等性重试 解决
Raft Timing
时间计算的 方式
- boardcastTime , avg of All(req,resp) , 0.5 ~ 20 ms
- electionTimout , 10 ~ 500ms
- MTBF , avg of failures
Raft cluster membership chageu ATTACH
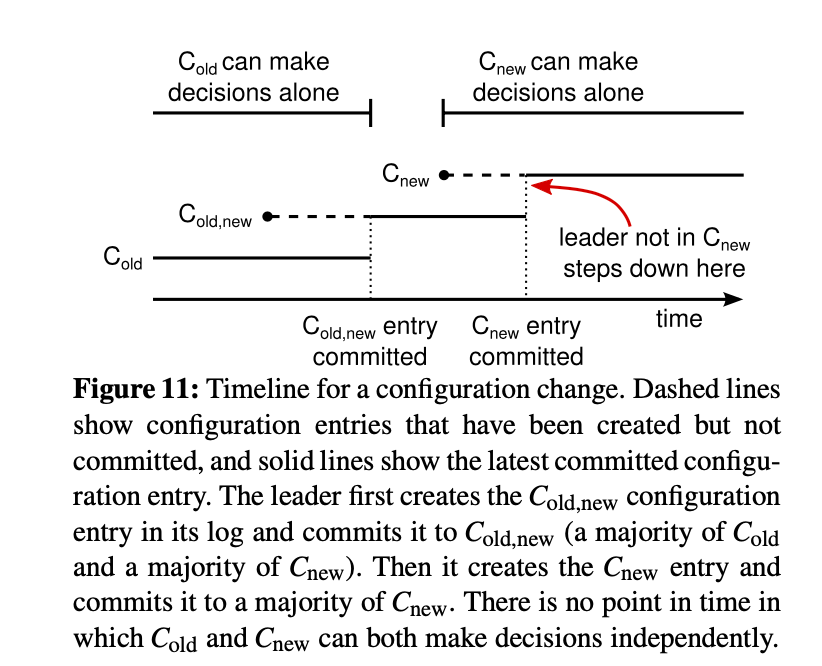
通过一致性算法自动处理配置变更 在变更过程中无法保障原子行修改,在切换过程中,集群会分裂成两个独立的大多数集群(Old,New)
Raft 采用了一种两阶段协议来保障安全性
joint consenus:
- 日志在 \( C_{\text{old}} \) 与 \( C_{\text{new}} \) 两个配置集群间都进行复制
- 任何来配置内的服务都可以作为 Leader
- 需要在新老配置的服务中都赢得大多数同意
会引入 3 个问题
- 新机器没有任何日志,会导致很长的 gap 时间 新加入的机器没有选举权,直到日志追平
- Leader 不在新配置中 在\( C_{\text{old}} \)被确认阶段,会被迫转为 follower ,复制日志,但不会把自己计入大多数中,等待新的 Leader
- 被移除的服务有可能分裂集群 服务在最小选举超时时间内,没有收到当前 Leader 的确认,不会跟新 term
Raft Log Compaction ATTACH

保存当前的状态值,以当前值开始重新进行日志的写追加
快照在集群间的处理难度
- follower 自行处理
- 统一由 Leader 处理
- Snapshot 的同步场景导致网络与程序延迟
- Leader 的复杂性
以及 2 个性能相关的问题
- 快照频率
- 写入快照的时间占用,COW 方案
Raft Client interaction
客户端在启动时,会随机选择一个服务,如果该服务不是 Leader ,会拒绝请求并返回其所知的最新的 Leader 信息
线性化语意
线性化语义(linearizable semantics)是分布式系统中使用的一种一致性模型,特别是在并发操作的上下文中。简单来说,线性化确保对共享资源(如变量或数据结构)的每个操作看起来都在某个时间点瞬间执行,并且在其调用和响应之间的某个时刻执行。线性化的关键点如下:
瞬时操作:每个操作必须看起来在其调用和响应之间的某个时间点瞬间执行,这个“时间点”被认为是操作完成的时刻。
操作顺序:资源上的操作必须遵循一个全局顺序,该顺序与它们的调用顺序一致。即使操作是并发执行的或在分布式系统中乱序执行,它们的结果也必须与某种顺序的执行一致。
原子性:每个操作看起来是原子的,即要么完全执行,要么完全不执行(没有部分结果)。
实时一致性:如果一个操作的响应在另一个操作的调用之前收到,那么第一个操作的结果必须对第二个操作可见,并且第二个操作开始时能看到第一个操作的结果。
通过顺序号来保证
Read-only 实现的两个必要措施
- Leader 需要知道最新的提交
Entryno-op entry - 处理 Read-only 请求前确保自己没有被罢免 通过心跳机制来保障